

博客2:模特对决
开源模式还是专有模式--哪种适合您?
AI 领域发展迅速,新机型层出不穷。其中的佼佼者包括 OpenAI 的 GPT-4o、Meta 的 LLaMA 3.1 和 Anthropic 的 Claude 3.5,它们各有千秋,满足了不同的需求。让我们进行一次正面比较,帮助您决定哪种型号最符合您的要求。
本文将对三种领先的 LLM 进行正面比较,探讨它们的开发、技术规格和性能,从而揭示它们的独特优势和局限性。

1.GPT-4o:多式联运中心
OpenAI 的 GPT-4o 在其前代产品成功的基础上,以真正 "全能 "的方式推动了 AI 的发展。它在多模式功能方面表现出色,能以惊人的速度和准确性处理实时语音对话和高级图像分析。这种多功能性使其成为从客户支持和创意内容生成到需要高扩展性的任务等各种应用的理想选择。
主要优势
- 多模态功能:可处理文本和图像,包括实时语音对话。
- 可扩展性:专为大容量任务和复杂应用而设计。
- 多功能性:适用于从客户服务到创意内容等各种用途。
潜在限制:
准确性需要验证:虽然功能强大,但偶尔也会生成不准确的信息,因此在执行关键任务时需要进行事实核查。
2.LLaMA 3.1:开源冠军
Meta 的 LLaMA 3.1 支持开源 AI 开发,使研究人员和开发人员能够访问强大的模型及其变体。LLaMA 3.1 拥有多达 4050 亿个参数,并在海量数据集上进行了训练,可与专有模型有效竞争,在长语境任务和多语言能力方面表现出色。
主要优势
- 开源访问:供研究人员和开发人员免费使用。
- 强大的性能:可处理复杂任务,包括长语境和多语言应用程序。
- 可扩展性:提供各种参数大小,满足不同需求。
潜在限制:
数据偏差:与所有大型语言模型一样,LLaMA 3.1 也是在可能包含偏差的海量数据集上进行训练的;
自托管性能:虽然它的功能非常强大,但如果托管在自己的服务器上,其性能可能会比商业机型稍慢。
3.克劳德 3.5:合乎道德的 AI 倡导者
Anthropic 的 Claude 3.5 Sonnet 将 AI 的道德开发和安全性放在首位,为负责任地使用 AI 设立了标准。它在编程任务和复杂推理基准测试中表现出色,展示了其处理细微查询和提供可靠、安全输出的能力。它的高级功能(如艺术品)增强了其交互能力,使其不再仅仅是一个生成工具,而是一个协作伙伴。
主要优势
- 道德 AI 焦点:优先考虑安全和准确的产出,严格遵守道德准则。
- 复杂推理:可处理细微查询,擅长编程和推理任务。
- 协作功能:提供互动功能,使其成为团队合作的重要工具。
潜在限制:
注重安全的设计:它对安全准则的严格遵守可能会导致它拒绝回答某些问题,这使它成为教育目的的理想选择,但也可能限制其在某些应用中的范围。
4.法律硕士的成本:开源与商业
虽然 Llama 3.1 70B 等开源模式具有免费使用、本地运行或通过托管服务提供商运行的优势,但商业模式一直在积极降低价格,使其竞争力日益增强。
OpenAI 的 GPT-4 Mini 功能强大但价格低廉,每百万 tokens 的价格仅为 $0.26。Gemini 1.5 Flash 和 Claude 3.5 Haiku 紧随其后,每百万 tokens 的价格分别为 $0.53 和 $0.50。
尽管运行开源模型的成本较低,但商用 LLM 的价格仍具有竞争力。这一趋势表明,获取功能强大的 AI 技术的成本正在降低,从而使更多用户和应用更容易获得这种技术。
5.性能对决:速度和延迟
在速度方面,LLaMA 3.1 70B 在 Groq 等提供商中大放异彩,实现了每秒 250 tokens 的惊人输出。其他供应商的速度通常在每秒 30 到 65 tokens 之间。
在延迟方面,GPT-4 Mini 约为 0.6 秒,而 Claude 3.5 Haiku 的延迟为 0.5 秒。LLaMA 3.1 70B 的延迟因提供商而异,从 0.28 秒到 1 秒不等。值得注意的是,Databricks、Octo、Fireworks 和 Deepinfra 等提供商在延迟方面优于商业模式,始终提供低于 0.5 秒的响应。
GPT-4o、Claude 3.5 和 Llama 3.1 的比较
| 型号特点 | GPT-4o | 克劳德 3.5 | 拉马 3.1 |
| 知识截止日期 | 2023 年 10 月 | 2024 年 4 月 | 在大量数据集上训练的开源模型,2023 年 12 月。 |
| 参数 | 200 多亿 | 估算
俳句(~20B)、 作品(~2T) |
8B/70B/405B |
| 多种模式 | 支持多模态功能,包括高级图像分析和实时语音对话 | 以文字为主,能够执行需要视觉推理的任务,如解读图表等 | 暂无 |
| 上下文窗口 | 128 000 个 token 作为输入、
4096 tokens 输出(由用户报告) |
200,000 tokens 输入、
输出上限设定为 4 096 tokens |
128 000 个 token 输入、
输出 不适用 |
LLM 领域得益于几个已被广泛接受的成熟基准。这些基准是评估模型性能、比较不同 LLM 和跟踪进展的重要工具。这些基准已成为 AI 社区的标准参考点。如果您对该领域感兴趣,请访问以下网站了解更多信息: 羊驼评估, 胶水, OpenLLM 排行榜.
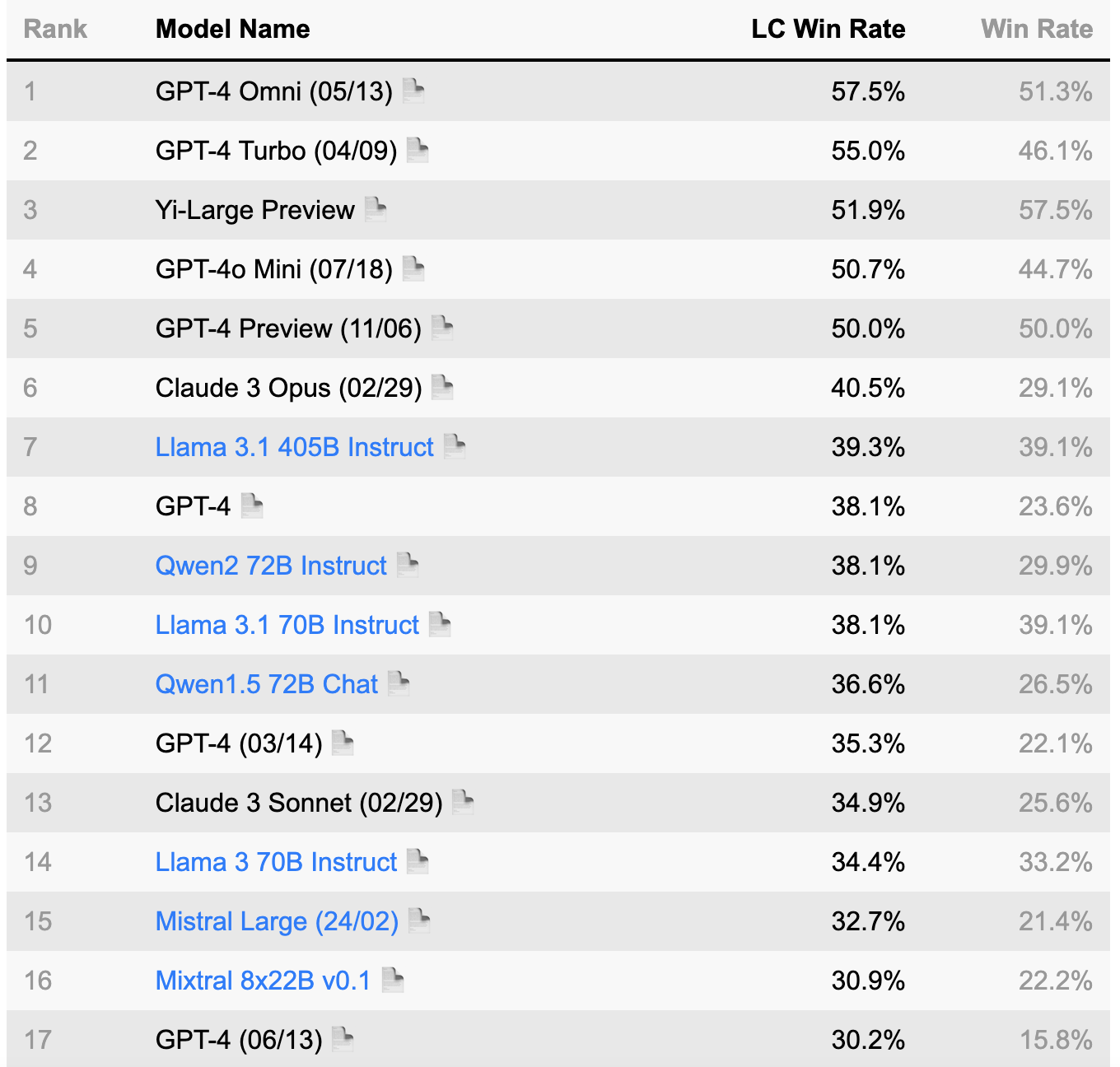
(资料来源:AlpacaEval 排行榜 https://tatsu-lab.github.io/alpaca_eval/)
6.结论: 选择正确的模式
最适合您的 AI 型号取决于您的具体需求和优先事项。
GPT-4o:适用于多模式任务、高扩展性以及需要高级图像和语音处理的应用。
LLaMA 3.1:对于寻求功能强大、开源、在长语境和多语言任务中表现出色的模型的研究人员和开发人员来说,这是一个极佳的选择。
克劳德 3.5:最适合优先考虑伦理因素、复杂问题解决和协作工作的应用。
本博客展示了开源模式和专有模式的优势。模式的选择最终取决于应用程序的具体需求。每种模式都有其独特的优缺点,因此最佳选择取决于您的具体要求。随着 AI 技术的不断发展,我们的未来将充满无限的创新和进步的可能。