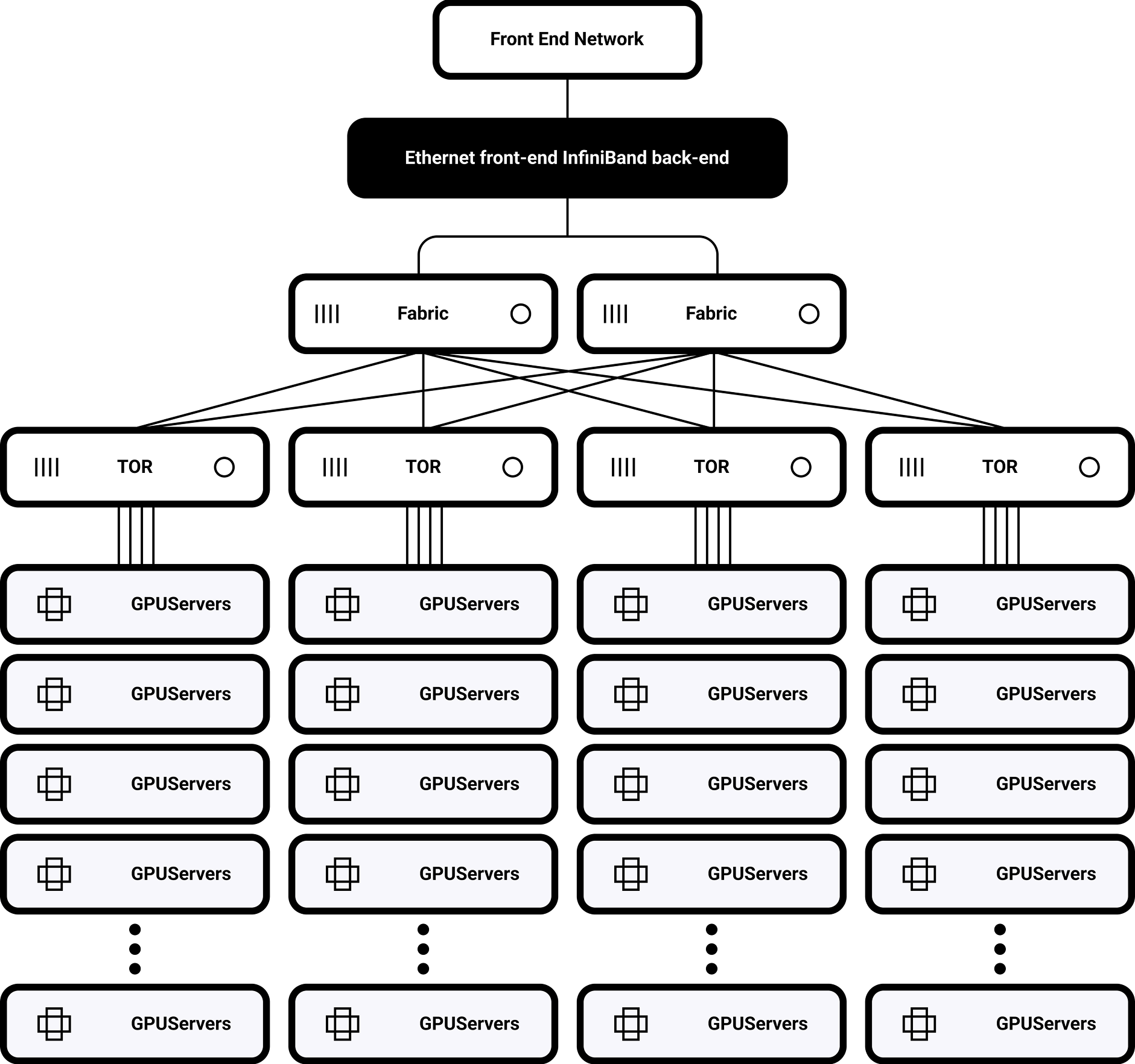

超低延迟架构
端到端延迟时间低至 0.8 微秒(比传统 TCP/IP 快 20 倍)
支持 200/400/800 Gbps InfiniBand 标准
拓扑感知调度
动态路由优化和机架间流量自动平衡 对 NCCL 库进行深度优化后,AllReduce 运算的加速度达到 40%
单机架拓扑结构
32 台 H100 GPU 通过 NVSwitch 实现完全互联
900GB/s 双向带宽
支持多集群扩展
基于 SHARP 的分布式路由
可扩展至 1,000-10,000 个节点
结果 175B 参数模型训练任务
通信开销从 35% 减少到 8%,机架间流量减少了 60%
尺寸
网络层
计算层
存储层
为了提供最佳体验,我们使用 cookies 等技术来存储和/或访问设备信息。同意使用这些技术将允许我们在本网站上处理浏览行为或唯一 ID 等数据。
您的 AI 之旅从这里开始。
请填写表格,我们会给您答复。