
Say goodbye to communication bottlenecks
Developing a sub-nanosecond AI compute network
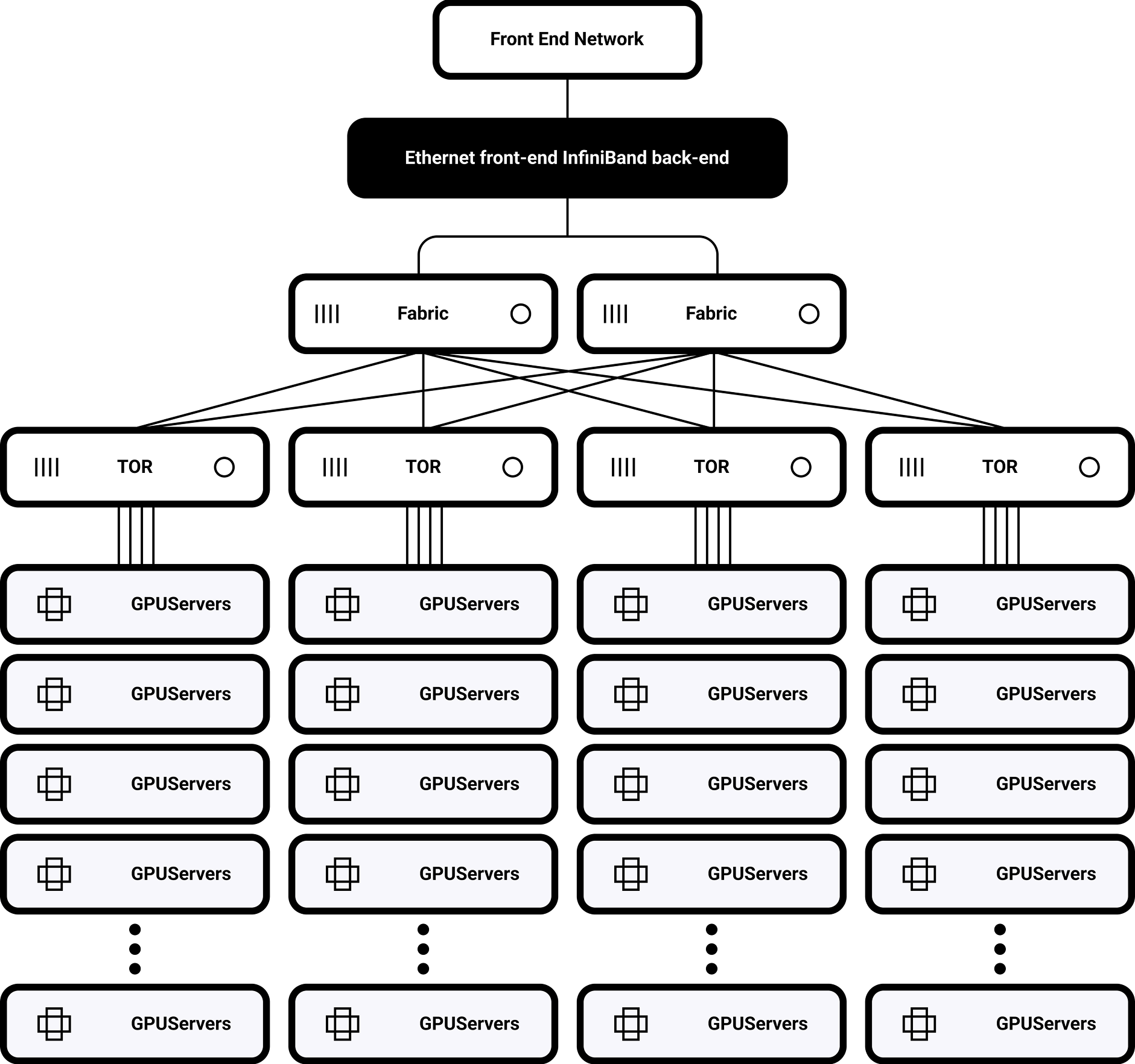
Ultra-Low Latency Architecture
End-to-end latency as low as 0.8 µs (20x faster than traditional TCP/IP)
Supports 200/400/800 Gbps InfiniBand standards
Topology-aware Scheduling
Dynamic routing optimization and automatic inter-rack traffic balancing Deep optimization of the NCCL library results in a 40% acceleration of AllReduce operations
Single-rack Topology
32 H100 GPUs fully interconnected via NVSwitch
900GB/s bisection bandwidth
Supports Multi-cluster Scaling
SHARP-based distributed routing
enabling expansion to 1,000-10,000 nodes
Results: 175B parameter model training task
communication overhead was reduced from 35% to 8%, inter-rack traffic was decreased by 60%
Dimensions
Network Layer
Compute Layer
Storage Layer
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site.
Your AI journey starts here.
Fill out the form and we’ll get back to you with answers.