

블로그2: 모델 대결:
오픈 소스 또는 독점 모델 - 어떤 것이 적합할까요?
AI 환경은 놀라운 속도로 새로운 모델이 등장하면서 빠르게 진화하고 있습니다. 선두 주자로는 OpenAI의 GPT-4o, Meta의 LLaMA 3.1, Anthropic의 Claude 3.5가 있으며, 각각 고유한 강점을 자랑하고 다양한 요구 사항을 충족합니다. 요구 사항에 가장 적합한 모델을 결정하는 데 도움이 되는 일대일 비교를 살펴보세요.
이 글에서는 세 가지 주요 LLM을 일대일로 비교하고 개발, 기술 사양 및 성능을 살펴봄으로써 각각의 고유한 강점과 한계를 살펴봅니다.

1. GPT-4o: 멀티모달의 강자
OpenAI의 GPT-4o는 전작의 성공을 바탕으로 진정한 '전능한' 접근 방식으로 AI의 한계를 뛰어넘었습니다. 실시간 음성 대화와 고급 이미지 분석을 인상적인 속도와 정확성으로 처리하는 멀티모달 기능에 탁월합니다. 이러한 다목적성 덕분에 고객 지원 및 크리에이티브 콘텐츠 생성부터 높은 확장성이 필요한 작업까지 다양한 애플리케이션에 이상적입니다.
주요 강점:
- 멀티모달 기능: 실시간 음성 대화를 포함하여 텍스트와 이미지를 모두 처리합니다.
- 확장성: 대용량 작업과 복잡한 애플리케이션을 위해 설계되었습니다.
- 다목적성: 고객 서비스부터 크리에이티브 콘텐츠에 이르기까지 다양한 사용 사례에 적합합니다.
잠재적 제한:
정확성에는 검증이 필요합니다: 강력하지만 때때로 부정확한 정보를 생성할 수 있으므로 중요한 작업에는 사실 확인이 필요합니다.
2. LLaMA 3.1: 오픈 소스 챔피언
Meta의 LLaMA 3.1은 오픈 소스 AI 개발을 지원하여 연구자와 개발자가 강력한 모델과 그 변종에 액세스할 수 있도록 지원합니다. 최대 4,050억 개의 파라미터와 방대한 데이터 세트에 대한 학습을 통해 LLaMA 3.1은 독점 모델과 효과적으로 경쟁하며, 긴 컨텍스트 작업과 다국어 기능에서 강력한 성능을 제공합니다.
주요 강점:
- 오픈 소스 액세스: 연구자와 개발자가 자유롭게 이용할 수 있습니다.
- 강력한 성능: 긴 컨텍스트 및 다국어 애플리케이션을 포함한 복잡한 작업을 처리합니다.
- 확장성: 다양한 요구사항에 맞게 다양한 매개변수 크기를 제공합니다.
잠재적 제한:
데이터 편향: 모든 대규모 언어 모델과 마찬가지로 LLaMA 3.1은 편향이 있을 수 있는 대규모 데이터 세트에 대해 학습됩니다;
자체 호스팅 성능: 매우 강력하지만 자체 서버에서 호스팅할 경우 상용 모델에 비해 성능이 약간 느릴 수 있습니다.
3. 클로드 3.5: 윤리적 AI 옹호자
Anthropic의 클로드 3.5 소네트는 윤리적인 AI 개발과 안전을 우선시하며 책임감 있는 AI 사용의 표준을 제시합니다. 프로그래밍 작업과 복잡한 추론 벤치마크에서 탁월한 성능을 발휘하여 미묘한 쿼리를 처리하고 안정적이고 안전한 결과물을 제공하는 능력을 입증합니다. 아티팩트와 같은 고급 기능은 인터랙티브 기능을 강화하여 단순한 생성 도구가 아닌 협업의 동반자로 자리매김합니다.
주요 강점:
- 윤리적 AI 초점: 안전하고 정확한 결과물을 우선시하며 엄격한 윤리 지침을 준수합니다.
- 복잡한 추론: 미묘한 쿼리를 처리하고 프로그래밍 및 추론 작업에 탁월합니다.
- 협업 기능: 대화형 기능을 제공하여 팀워크를 위한 유용한 도구입니다.
잠재적 제한:
안전에 중점을 둔 디자인: 안전 지침을 엄격하게 준수하기 때문에 특정 질문을 거부할 수 있어 교육 목적으로는 이상적이지만 일부 애플리케이션에서는 사용 범위가 제한될 수 있습니다.
4. LLM의 비용: 오픈 소스 대 상용
Llama 3.1 70B와 같은 오픈 소스 모델은 로컬 또는 호스팅 제공업체를 통해 무료로 사용 및 실행할 수 있다는 장점이 있지만, 상용 모델은 가격을 공격적으로 낮추고 있어 경쟁이 치열해지고 있습니다.
OpenAI의 GPT-4 Mini는 강력하면서도 저렴한 옵션으로 token 백만 개당 가격이 $0.26달러에 불과합니다. 제미니 1.5 플래시와 클로드 3.5 하이쿠가 그 뒤를 따르고 있으며, 가격은 각각 token 백만 개당 $0.53과 $0.50입니다.
오픈 소스 모델의 운영 비용이 낮아졌음에도 불구하고 상용 LLM은 여전히 경쟁력 있는 가격을 유지하고 있습니다. 이러한 추세는 강력한 AI 기술에 액세스하는 데 드는 비용이 감소하여 더 많은 사용자와 애플리케이션이 더 쉽게 접근할 수 있게 되었다는 것을 의미합니다.
5. 성능 대결: 속도 및 지연 시간
속도 면에서 LLaMA 3.1 70B는 초당 250 token의 인상적인 출력을 달성하는 Groq과 같은 제공업체에서 빛을 발합니다. 다른 공급업체는 일반적으로 초당 30~65 token의 속도를 제공합니다.
지연 시간 측면에서 GPT-4 Mini는 약 0.6초, Claude 3.5 하이쿠는 0.5초의 지연 시간을 기록합니다. LLaMA 3.1 70B의 지연 시간은 제공업체에 따라 0.28초에서 1초 사이로 다양합니다. 특히 데이터브릭스, 옥토, 파이어웍스, 딥인프라와 같은 제공업체는 지연 시간에서 상용 모델보다 우수한 성능을 보이며 0.5초 미만의 응답을 일관되게 제공합니다.
GPT-4o, 클로드 3.5, 라마 3.1의 비교
| 모델 기능 | GPT-4o | Claude 3.5 | 라마 3.1 |
| 지식 마감일 | 2023년 10월 | 2024년 4월 | 광범위한 데이터 세트로 학습된 오픈 소스 모델, 2023년 12월. |
| 매개변수 | 200억 이상 | 견적
하이쿠(~20B), 오퍼스(~2T) |
8B/70B/405B |
| 멀티 모델 | 고급 이미지 분석 및 실시간 음성 대화를 포함한 멀티모달 기능 지원 | 주로 텍스트, 차트 및 그래프 해석과 같은 시각적 추론이 필요한 작업을 수행할 수 있습니다. | 현재 사용할 수 없습니다. |
| 컨텍스트 창 | 128,000개의 token를 입력으로 사용합니다,
4096 token 출력(사용자 보고) |
200,000개의 token 입력,
출력 제한이 4,096 token로 설정됨 |
128,000개의 token 입력,
출력 N/A |
LLM 분야는 널리 인정받고 있는 몇 가지 잘 정립된 벤치마크의 혜택을 받고 있습니다. 이러한 벤치마크는 모델 성능을 평가하고, 서로 다른 LLM을 비교하고, 진행 상황을 추적하는 데 중요한 도구로 사용됩니다. 이러한 벤치마크는 AI 커뮤니티 내에서 표준 기준점이 되었습니다. 이 분야에 관심이 있으신 분은 다음에서 자세한 정보를 확인할 수 있습니다: 알파카에볼, 접착제, OpenLLM 리더보드.
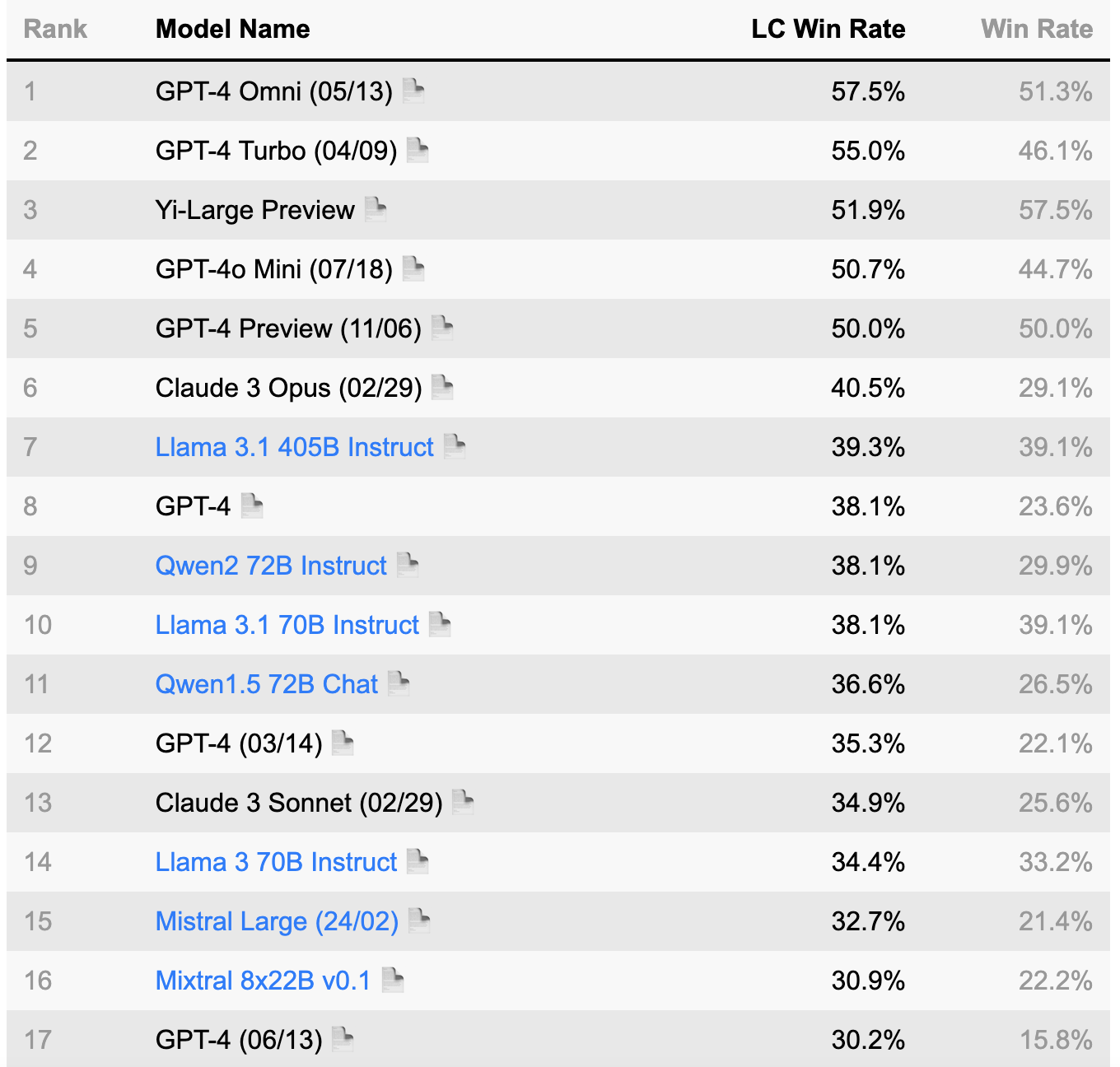
(출처: 알파카에볼 리더보드 https://tatsu-lab.github.io/alpaca_eval/)
6. 결론: 적합한 모델 선택
가장 적합한 AI 모델은 특정 요구 사항과 우선순위에 따라 다릅니다.
GPT-4o: 멀티모달 작업, 높은 확장성, 고급 이미지 및 음성 처리가 필요한 애플리케이션에 이상적입니다.
LLaMA 3.1: 긴 컨텍스트 및 다국어 작업에서 강력한 성능을 발휘하는 강력한 오픈 소스 모델을 찾는 연구자와 개발자에게 탁월한 선택입니다.
Claude 3.5: 윤리적 고려 사항, 복잡한 문제 해결 및 공동 작업을 우선시하는 애플리케이션에 가장 적합합니다.
이 블로그에서는 오픈 소스 모델과 독점 모델의 강점을 모두 보여드리며, 모델 선택은 궁극적으로 애플리케이션의 특정 요구 사항에 따라 달라집니다. 각 모델마다 고유한 장단점이 있으므로 특정 요구사항에 따라 최선의 선택을 해야 합니다. AI 기술이 계속 성장함에 따라 혁신과 발전의 가능성이 무궁무진한 흥미로운 미래가 기다리고 있습니다.