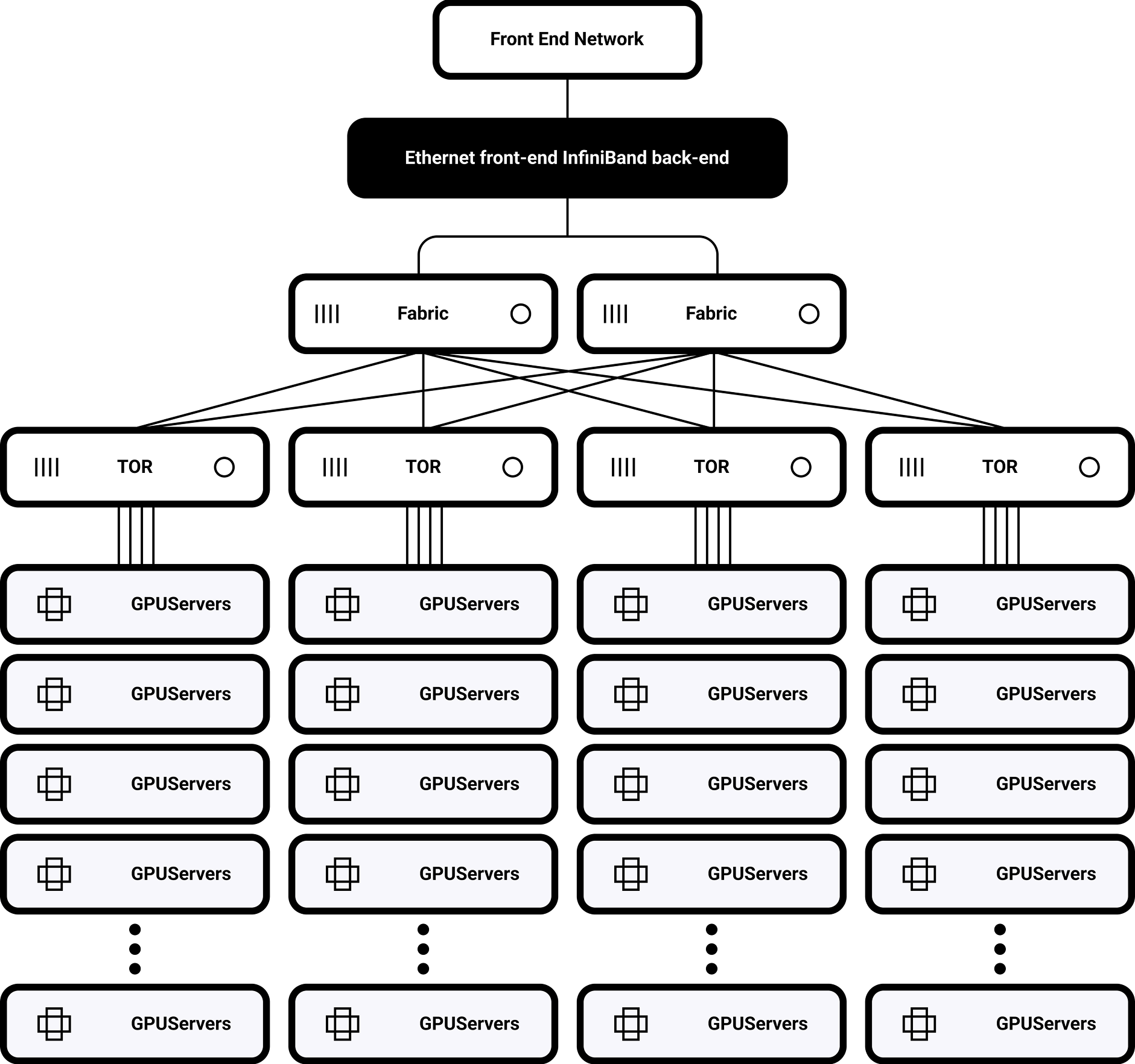

초저지연 아키텍처
0.8µs의 낮은 엔드투엔드 지연 시간(기존 TCP/IP보다 20배 빠름)
200/400/800Gbps 인피니밴드 표준 지원
토폴로지 인식 스케줄링
동적 라우팅 최적화 및 자동 랙 간 트래픽 밸런싱 NCCL 라이브러리의 심층 최적화를 통해 AllReduce 작업의 40% 가속화를 실현합니다.
단일 랙 토폴로지
NVSwitch를 통해 완전히 상호 연결된 32개의 H100 GPU
900GB/s 양방향 대역폭
멀티 클러스터 확장 지원
SHARP 기반 분산 라우팅
1,000~10,000개 노드로 확장 가능
결과: 175B 매개변수 모델 학습 작업
통신 오버헤드는 35%에서 8%로 감소했고, 랙 간 트래픽은 60% 감소했습니다.
치수
네트워크 계층
컴퓨팅 레이어
스토리지 계층
최상의 경험을 제공하기 위해 당사는 쿠키와 같은 기술을 사용하여 기기 정보를 저장 및/또는 액세스합니다. 이러한 기술에 동의하면 이 사이트에서 검색 행동이나 고유 ID와 같은 데이터를 처리할 수 있습니다.
AI 여정은 여기서 시작됩니다.
양식을 작성해 주시면 답변을 보내드리겠습니다.