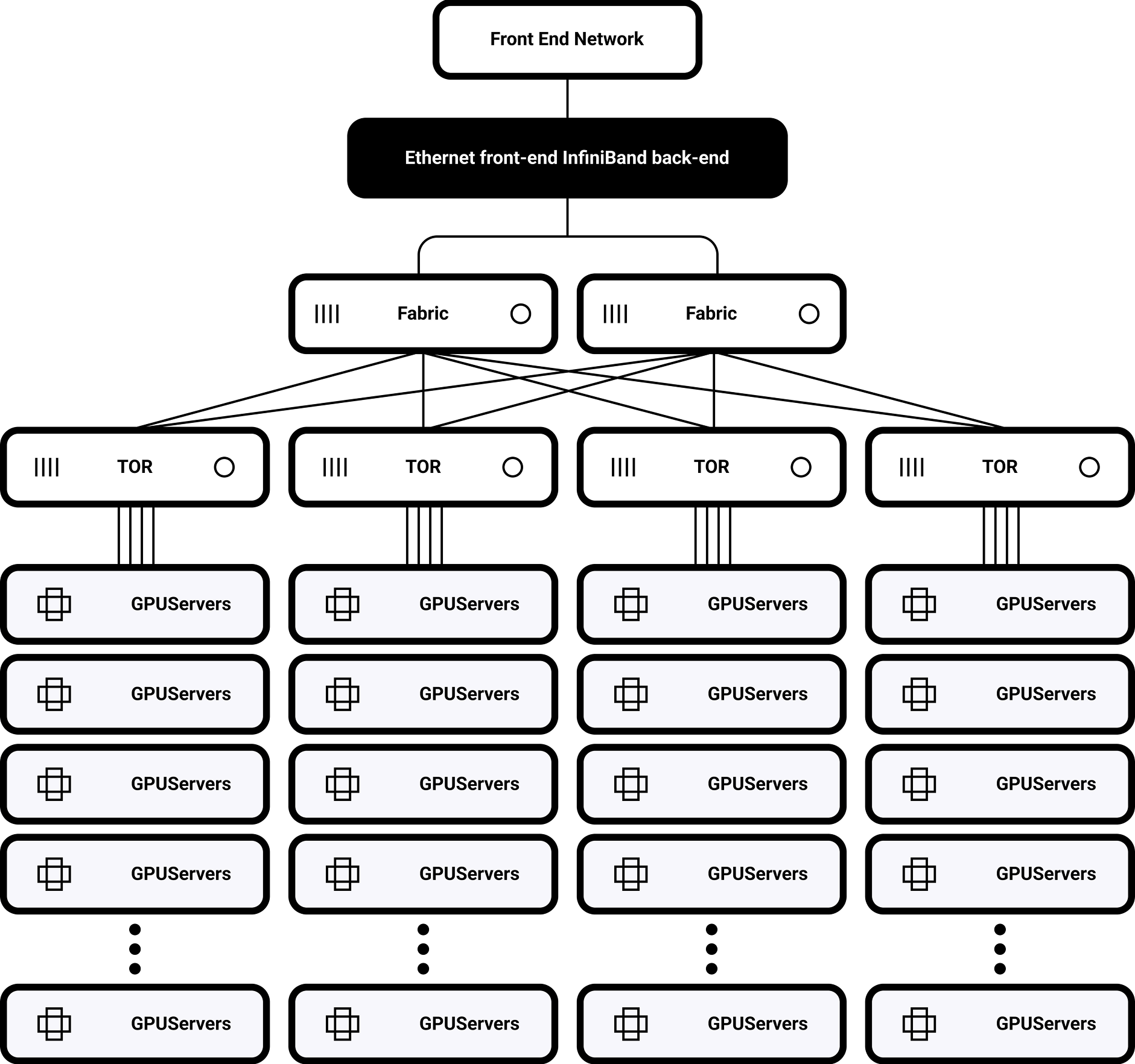

超低遅延アーキテクチャ
エンド・ツー・エンドのレイテンシは0.8 µsと低い(従来のTCP/IPの20倍高速)
200/400/800 Gbps InfiniBand規格に対応
トポロジーを考慮したスケジューリング
ダイナミック・ルーティングの最適化と自動ラック間トラフィック・バランシング NCCLライブラリの深い最適化により、AllReduceオペレーションを40%高速化
シングルラックトポロジー
32台のH100 GPUをNVSwitchで完全相互接続
900GB/秒のバイセクション帯域幅
マルチクラスター・スケーリングをサポート
SHARPベースの分散ルーティング
1,000~10,000ノードへの拡張が可能
結果 175Bパラメータ・モデルのトレーニング・タスク
通信オーバーヘッドは35%から8%に減少し、ラック間トラフィックは60%減少した。
寸法
ネットワーク層
コンピュート・レイヤー
ストレージ層
最高の体験を提供するために、当社はクッキーのような技術を使用してデバイス情報を保存および/またはアクセスします。これらの技術に同意することで、当サイトの閲覧行動や固有IDなどのデータを処理することができます。
あなたのAIの旅はここから始まる。
フォームに必要事項をご記入ください。