

ブログ2:モデル対決:
オープンソースとプロプライエタリ・モデル - どちらが適しているか?
AIは急速に進化しており、驚くほどのスピードで新しいモデルが登場している。中でもOpenAIのGPT-4o、MetaのLLaMA 3.1、AnthropicのClaude 3.5は、それぞれ独自の強みを誇り、異なるニーズに対応している。どのモデルがあなたの要件に最も適しているか、直接比較してみましょう。
この記事では、代表的な3つのLLMを正面から比較し、それぞれの開発、技術仕様、パフォーマンスを探ることで、独自の強みと限界を明らかにする。

1.GPT-4oマルチモーダル大国
OpenAIのGPT-4oは、先代の成功に基づき、真に「全能」なアプローチでAIの限界を押し広げます。マルチモーダルな機能性に優れ、リアルタイムの音声会話や高度な画像解析を素晴らしいスピードと精度で処理します。この汎用性により、カスタマーサポートやクリエイティブなコンテンツ生成から、高い拡張性を必要とするタスクまで、幅広いアプリケーションに最適です。
主な強み
- マルチモーダル機能:リアルタイムの音声会話を含む、テキストと画像の両方を扱う。
- スケーラビリティ:大量のタスクや複雑なアプリケーション向けに設計されています。
- 汎用性:カスタマーサービスからクリエイティブなコンテンツまで、幅広い用途に対応。
潜在的な制限:
正確さには検証が必要:強力な反面、不正確な情報を生成することもあるため、重要な作業には事実確認が必要となる。
2.LLaMA 3.1: オープンソース・チャンピオン
Meta社のLLaMA 3.1は、オープンソースのAI開発を支援し、研究者や開発者が強力なモデルとその亜種にアクセスできるようにします。LLaMA 3.1は、最大4,050億のパラメータと膨大なデータセットでのトレーニングにより、独自のモデルと効果的に競合し、ロングコンテキストのタスクと多言語機能において強力なパフォーマンスを提供します。
主な強み
- オープンソースアクセス:研究者や開発者が自由に構築できる。
- 堅牢なパフォーマンス:ロングコンテクストや多言語アプリケーションを含む複雑なタスクを処理します。
- スケーラビリティ:さまざまなニーズに合わせて、さまざまなパラメータサイズを提供します。
潜在的な制限:
データの偏り:他の大規模言語モデルと同様、LLaMA 3.1は、偏りを含む可能性のある膨大なデータセットで学習される;
自己ホスティングのパフォーマンス:驚くほどパワフルな反面、商用モデルに比べ、自社サーバーでホスティングした場合、パフォーマンスが若干低下する可能性があります。
3.クロード 3.5: 倫理的な AI 擁護者
AnthropicのClaude 3.5 Sonnetは、倫理的なAI開発と安全性を優先し、責任あるAI使用の基準を設定します。プログラミングタスクや複雑な推論ベンチマークに優れており、微妙なクエリを処理し、信頼性の高い安全な出力を提供する能力を示しています。Artifactsのような先進的な機能は、インタラクティブな機能を強化し、単なる生成ツールではなく、共同作業者としての位置づけです。
主な強み
- 倫理的なAIを重視する:安全で正確なアウトプットを優先し、厳格な倫理指針を遵守する。
- 複雑な推論:ニュアンスの異なるクエリを処理し、プログラミングや推論タスクに秀でる。
- コラボレーション機能:インタラクティブな機能を提供し、チームワークのための貴重なツールとなる。
潜在的な制限:
安全重視の設計:安全ガイドラインに厳格に準拠しているため、特定の質問を拒否する可能性があり、教育目的には理想的ですが、用途によってはその範囲が制限される可能性があります。
4.LLMのコストオープンソース vs. 商用
Llama 3.1 70Bのようなオープンソース・モデルは、ローカルで、あるいはホスティング・プロバイダーを通じて、無料で使用・実行できるという利点がある一方で、商用モデルは積極的に価格を下げており、競争力を増している。
OpenAIのGPT-4 Miniは、100万tokenあたりわずか$0.26と、パワフルでありながら手頃な価格のオプションとして際立っている。Gemini 1.5 FlashとClaude 3.5 Haikuは、それぞれ100万tokenあたり$0.53と$0.50で、僅差で続く。
オープンソース・モデルの実行コストが低下しているにもかかわらず、商用LLMは依然として競争力のある価格を維持している。この傾向は、強力なAI技術にアクセスするコストが低下し、より幅広いユーザーやアプリケーションがアクセスしやすくなっていることを示唆している。
5.パフォーマンス対決:スピードとレイテンシー
速度に関しては、LLaMA 3.1 70BはGroqのようなプロバイダーで輝きを放ち、毎秒250 tokensという驚異的な出力を達成している。他のプロバイダーでは、通常、毎秒30から65のtokensの速度です。
待ち時間に関しては、GPT-4 Miniは約0.6秒で、Claude 3.5 Haikuは0.5秒です。LLaMA 3.1 70Bのレイテンシはプロバイダーによって異なり、0.28秒から1秒の範囲である。注目すべきは、Databricks、Octo、Fireworks、Deepinfraのようなプロバイダーが、レイテンシにおいて商用モデルを凌駕していることで、常に0.5秒以下のレスポンスを実現している。
GPT-4o、クロード3.5、ラマ3.1の比較
| モデルの特徴 | GPT-4o | クロード 3.5 | ラマ 3.1 |
| ナレッジ締切日 | 2023年10月 | 2024年4月 | 2023年12月、広範なデータセットで訓練されたオープンソースのモデル。 |
| パラメータ | 200億ドル以上 | 見積もり
俳句(~20B)、 オーパス(~2T) |
8B/70B/405B |
| マルチモデル | 高度な画像解析やリアルタイムの音声会話を含むマルチモーダル機能をサポート | 文字が中心で、図表の解釈など視覚的な推論が必要な仕事をこなせる | 現在入手不可 |
| コンテキスト・ウィンドウ | 128,000 tokenを入力、
4096 token出力(ユーザー報告) |
200,000 tokens入力、
出力リミットを4096 tokensに設定 |
128,000 tokens入力、
出力 |
LLMの分野では、いくつかの確立されたベンチマークが広く受け入れられている。これらのベンチマークは、モデルの性能を評価し、異なるLLMを比較し、進歩を追跡するための重要なツールとなっている。これらのベンチマークは、AIコミュニティにおける標準的な参照点となっています。この分野にご興味のある方は、以下をご覧ください: アルパカ・エバール, グルーオープンLLM リーダーボード.
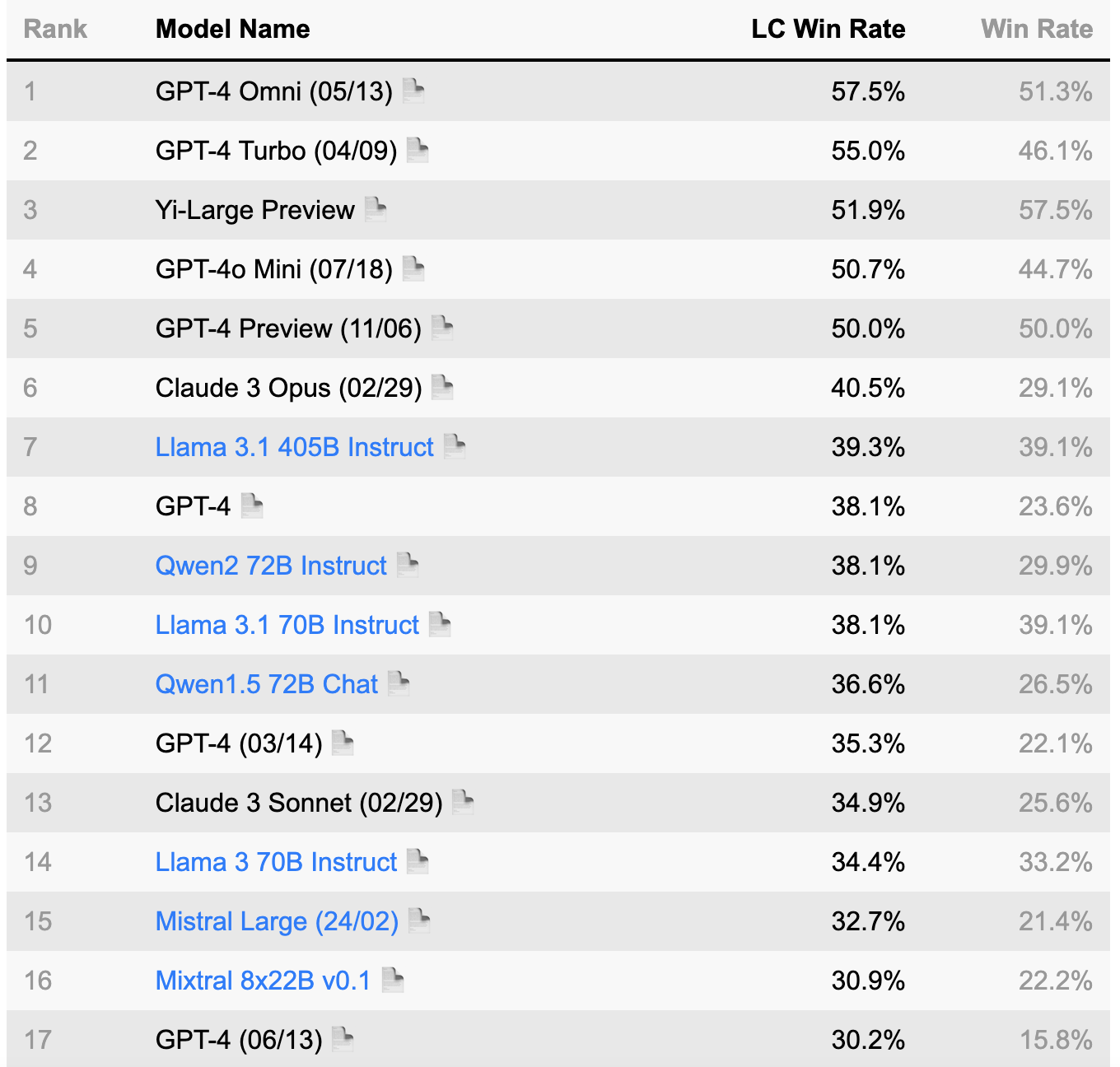
(出典:AlpacaEval リーダーボード https://tatsu-lab.github.io/alpaca_eval/)
6.結論 正しいモデルの選択
あなたに最適なAIモデルは、特定のニーズと優先事項によって異なります。
GPT-4o:マルチモーダルなタスク、高い拡張性、高度な画像・音声処理を必要とするアプリケーションに最適。
LLaMA 3.1:ロングコンテクスト、多言語タスクで強力な性能を発揮する、強力なオープンソースモデルを求める研究者、開発者にとって最適な選択肢。
Claude 3.5: 倫理的配慮、複雑な問題解決、共同作業を優先する用途に最適。
このブログでは、オープンソースとプロプライエタリ・モデルの両方の長所を示す。モデルの選択は、最終的にはアプリケーションの特定のニーズに依存する。各モデルには独自の長所と短所があり、最良の選択は特定の要件に依存します。AI技術が成長を続ける中、イノベーションと進歩の無限の可能性を秘めたエキサイティングな未来が待っています。