
Dites adieu aux goulets d'étranglement en matière de communication
Développement d'un réseau de calcul AI d'une durée inférieure à la nanoseconde
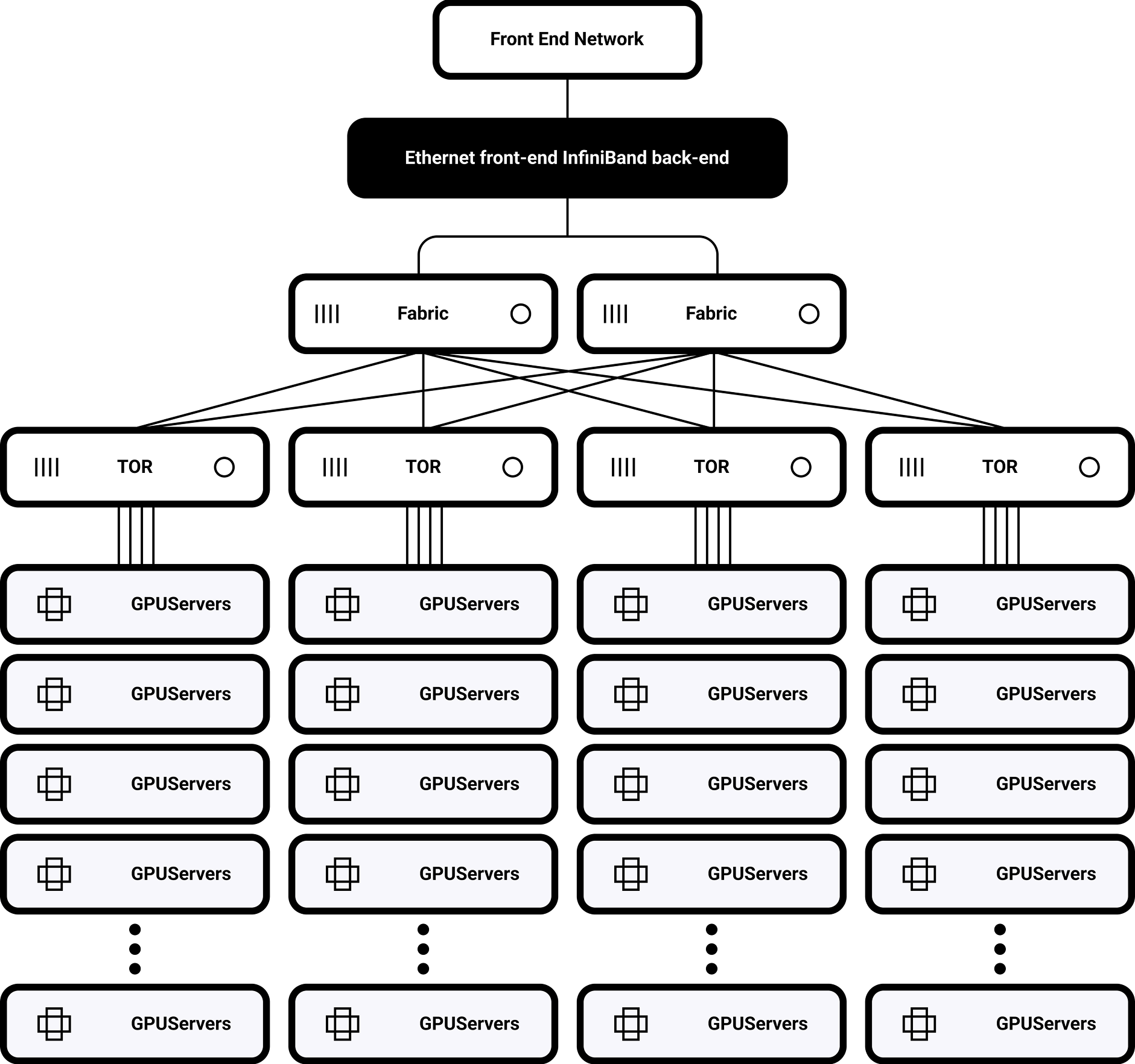
Architecture à très faible latence
Temps de latence de bout en bout aussi bas que 0,8 µs (20 fois plus rapide que le TCP/IP traditionnel)
Prise en charge des normes InfiniBand à 200/400/800 Gbps
Ordonnancement tenant compte de la topologie
Optimisation dynamique du routage et équilibrage automatique du trafic entre les racks L'optimisation en profondeur de la bibliothèque NCCL se traduit par une accélération de 40% des opérations AllReduce.
Topologie à un seul rack
32 H100 GPU entièrement interconnectés via NVSwitch
Bande passante de bissection de 900GB/s
Prise en charge de la mise à l'échelle de plusieurs clusters
Routage distribué basé sur SHARP
permettant une extension à 1 000-10 000 nœuds
Résultats : Tâche d'apprentissage du modèle de paramètres 175B
le surdébit de communication a été réduit de 35% à 8%, le trafic inter-racks a été réduit de 60%
Dimensions
Couche réseau
Couche de calcul
Couche de stockage
Afin de fournir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations relatives à l'appareil. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou des identifiants uniques sur ce site.
Votre voyage AI commence ici.
Remplissez le formulaire et nous vous répondrons.