
Diga adiós a los cuellos de botella en las comunicaciones
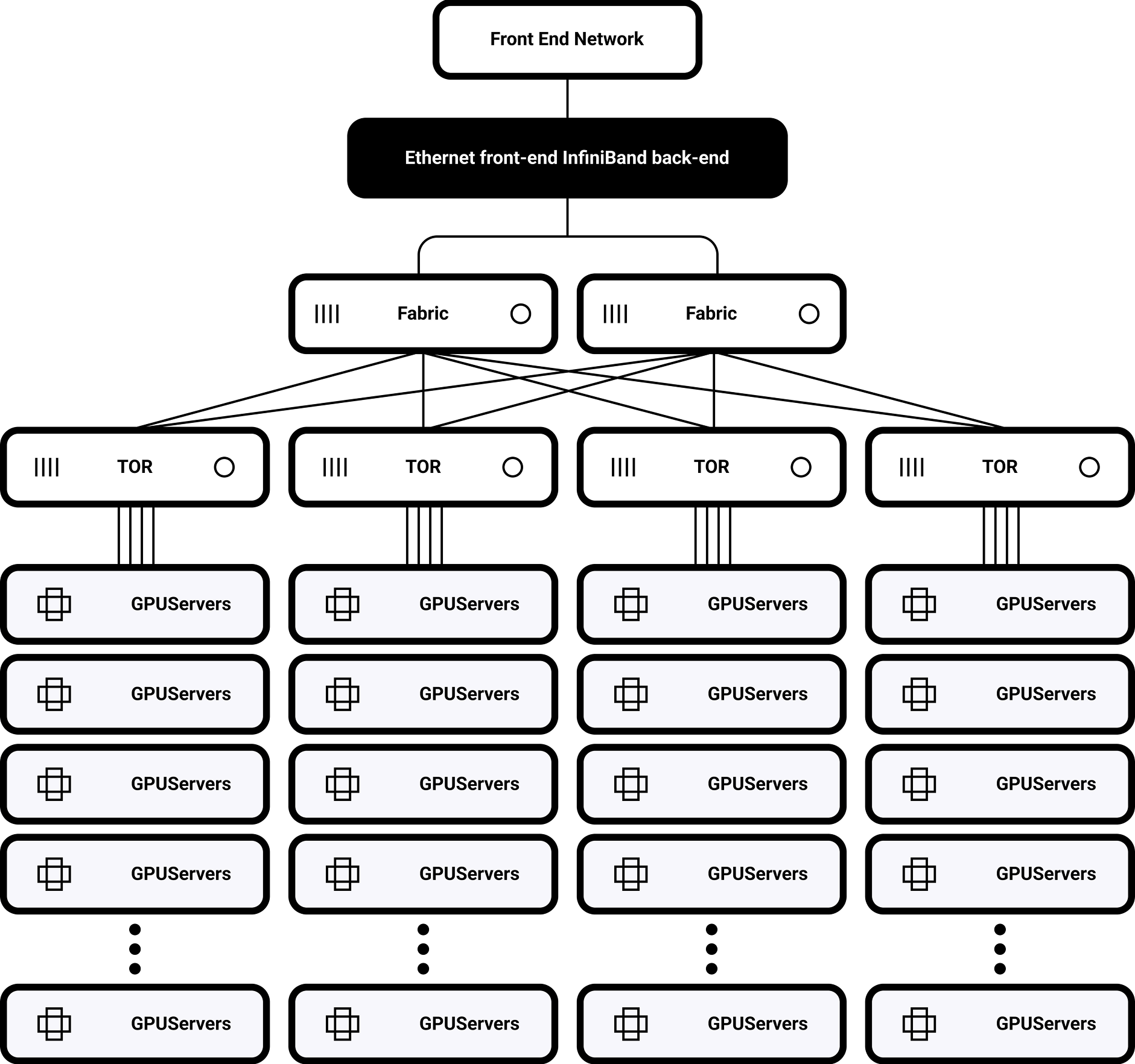
Desarrollo de una red informática AI de subnanosegundos
Arquitectura de latencia ultrabaja
Latencia de extremo a extremo tan baja como 0,8 µs (20 veces más rápido que el TCP/IP tradicional)
Compatible con los estándares InfiniBand 200/400/800 Gbps
Programación en función de la topología
Optimización dinámica del enrutamiento y equilibrio automático del tráfico entre bastidores La profunda optimización de la biblioteca NCCL da como resultado una aceleración 40% de las operaciones AllReduce
Topología de bastidor único
32 H100 GPU totalmente interconectados mediante NVSwitch
Ancho de banda de bisección de 900 GB/s
Admite escalado multiclúster
Enrutamiento distribuido basado en SHARP
permite la ampliación a 1.000-10.000 nodos
Resultados: Tarea de entrenamiento del modelo de parámetros 175B
la sobrecarga de comunicación se redujo de 35% a 8%, el tráfico entre bastidores disminuyó en 60%
Dimensiones
Capa de red
Capa informática
Capa de almacenamiento
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. Consentir estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o identificaciones únicas en este sitio.
Su viaje AI comienza aquí.
Rellene el formulario y le responderemos.